Speech to Text Software: Boost Productivity with the Right Tool
Ever wished you had a personal assistant who could instantly type out every word you say? That's pretty much what speech-to-text software does. It’s the technology that turns your spoken language into written text right before your eyes, letting you dictate emails, get a transcript of a meeting, or control your smart devices using just your voice.
What Is Speech To Text Software?
At its heart, speech-to-text software is a game-changer for how we create documents. It gives us the power to easily convert voice notes to text, which makes getting things down on paper (or screen) incredibly fast and accessible.
Think of it as a super-fast translator. It listens to one language—your spoken words—and fluently converts it into another—written text. This technology is often called Automatic Speech Recognition (ASR), and it's the engine running behind the scenes of virtual assistants, live video captions, and modern dictation tools.
The journey from a spoken idea to an editable document happens in a few distinct steps. It all starts the moment you speak into a microphone. The software captures the sound waves of your voice and turns them into a digital signal, which it then chops up into tiny, manageable segments.
A Look Under The Hood
So, how does the magic really happen? Let's break down the basic workflow.
| Component | Function | Analogy |
|---|---|---|
| Acoustic Model | Captures your voice's sound waves and converts them into digital signals, identifying basic sound units called phonemes. | This is like the system's "ear." It listens to the raw sounds, not the words themselves, just like you might hear individual notes before recognizing a song. |
| Language Model | Takes the phonemes and uses statistical probability to assemble them into words and then into logical sentences. | This is the "brain" of the operation. It acts like a predictive text engine, figuring out that "ice," "cream," and "sundae" are more likely to appear together than "ice," "scream," and "sun-day." |
| Text Output | Delivers the final, formatted text to your screen, ready for you to use or edit. | This is the final product—the neatly typed transcript appearing in your document or message. |
This process, from sound to sentence, is what allows the software to take what you say and turn it into something you can read and share.
The infographic below offers a great visual of this simple but powerful workflow.
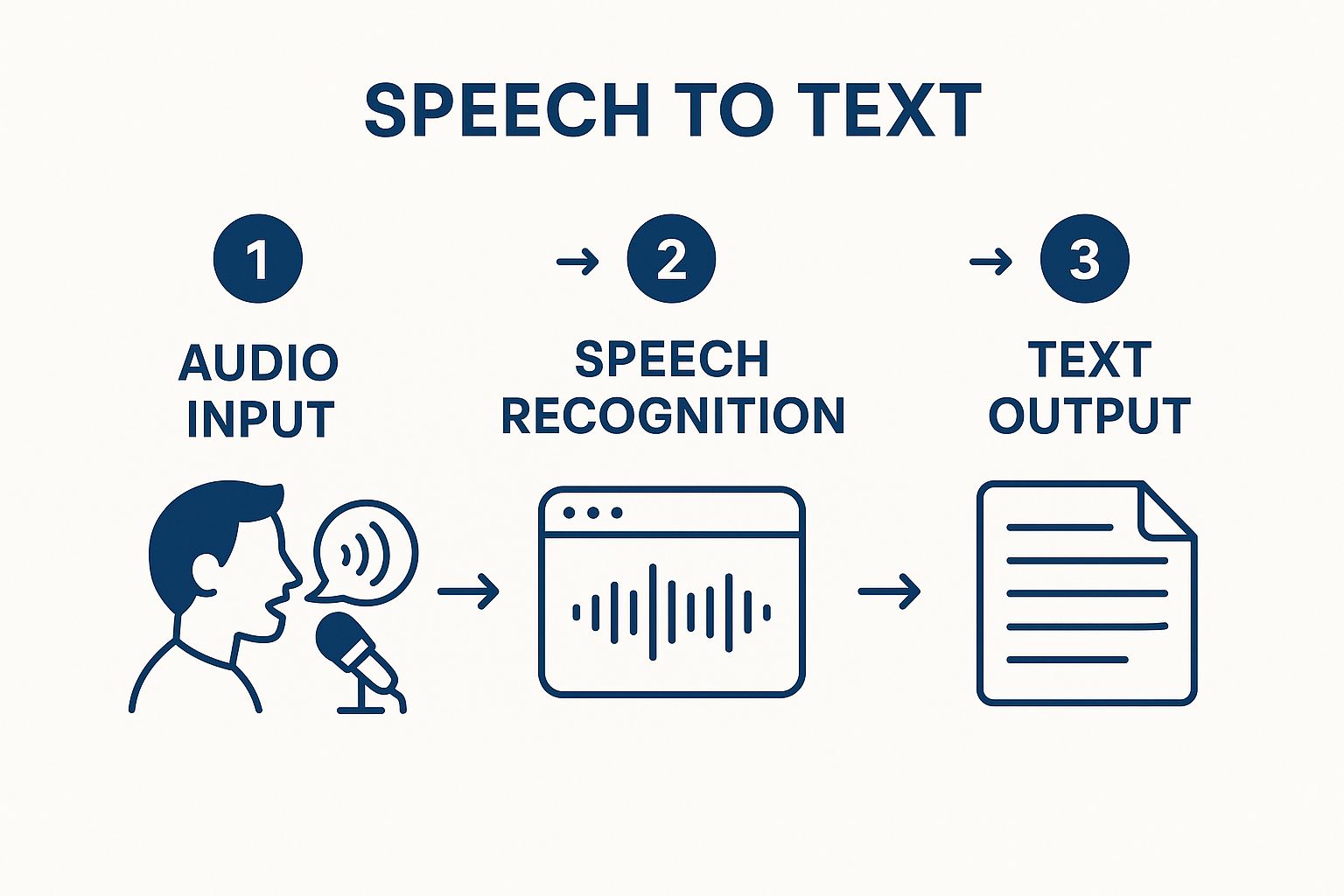
As you can see, the technology seamlessly moves from your voice input to a finished text output, taking the manual labor out of documentation.
Today’s ASR systems are a world away from the clunky, error-filled tools of the past. Thanks to huge leaps in artificial intelligence and machine learning, modern speech-to-text software can hit accuracy rates over 95% in the right conditions.
From Niche Gadget To Must-Have Tool
That high level of accuracy has been transformative. Speech-to-text has gone from a niche accessibility feature to a productivity tool used by millions. This rocketing popularity is reflected in the market's explosive growth.
This isn't just a small trend. The global market for speech-to-text technology is expected to grow by about 14.1% annually, on track to hit nearly USD 8.57 billion by 2030.
This boom is happening because industries everywhere are adopting it. In legal and healthcare, for example, it’s become indispensable for creating accurate, detailed records without the drag of manual typing. For doctors and nurses, specialized tools like medical dictation software are essential for capturing patient notes.
Ultimately, this technology lets professionals put their focus back where it belongs—on their core work, not on tedious paperwork.
The AI Engine Driving Modern Transcription

To really get what makes modern speech to text software so powerful, you have to peek behind the curtain at the engine running the show. The accuracy we see today feels like magic, but it’s actually the product of sophisticated Artificial Intelligence (AI). Think of it like teaching a person a new language—it takes a massive amount of training and practice to get it right.
This whole process boils down to two key AI components working together: an Acoustic Model and a Language Model. They’re a dynamic duo, turning the sounds you make into the words you see on the screen.
The Acoustic Model: The Sound Expert
The acoustic model is the system’s ear. Its one and only job is to listen to the audio and chop it up into the smallest units of sound, called phonemes. For instance, the word "cat" has three distinct phonemes: the "k" sound, the "æ" sound, and the "t" sound. Simple, right?
But to get good at this, the model has to be trained on thousands of hours of real human speech. We're talking a huge variety of voices, accents, and speaking styles. By digging through this mountain of data, it learns the specific acoustic fingerprints of each sound, no matter who’s talking, how fast they’re speaking, or if there's a bus driving by in the background.
The Language Model: The Context Guru
Okay, so the acoustic model has done its part and identified the raw sounds. Now the language model steps in. This is the brain of the operation, tasked with piecing those sounds together into words and sentences that actually make sense. It’s like a supercharged predictive text engine, constantly figuring out which word is most likely to come next.
Let's say it hears sounds that could be "two," "to," or "too." How does it decide? It looks at the surrounding words for clues.
- If you say, "I want to go to the store," it picks up on the context of movement.
- But if you say, "I want two apples," it understands you're talking about quantity.
This contextual awareness comes from being trained on enormous libraries of text—books, articles, websites, you name it. This is a core part of what makes Natural Language Processing (NLP) so effective, allowing software to understand language almost like a human would. It’s the secret sauce that lets the best tools nail homophones and deliver a transcript that’s grammatically sound.
Key Takeaway: Top-tier transcription isn't just about hearing sounds correctly. It's about understanding context, grammar, and the probability of words appearing together, all driven by powerful AI.
This partnership between sound recognition and contextual analysis is what separates a basic dictation app from a professional-grade transcription platform. It's a complex process, but the results speak for themselves. If you're curious about what this looks like from a user's perspective, our guide on https://www.whisperit.ai/blog/how-to-transcribe-audio-to-text breaks down the practical steps.
Training for Real-World Complexity
The quality of any transcription AI is a direct reflection of its training. The best systems aren't just fed clean audio in a quiet room; they are trained on the messy, complicated audio of the real world.
This means teaching the AI to handle:
- Multiple Speakers: Telling one person's voice from another in a busy meeting.
- Accents and Dialects: Understanding the nuances of how people talk in different regions.
- Background Noise: Ignoring distracting sounds like coffee shop chatter or street traffic.
- Industry Jargon: Recognizing specialized terms used in fields like medicine or law.
By constantly learning from these challenging situations, the AI gets smarter and more dependable. It learns to see patterns, filter out the noise, and produce a clean, accurate transcript even when the audio quality is less than perfect. This ongoing refinement is what has made modern speech to text software such a vital tool for so many professionals.
Key Features of Effective STT Software

It’s one thing to understand the AI that makes transcription possible, but knowing what features to look for when you're actually choosing a tool? That's what really counts. After all, not all speech to text software is built the same.
Think of this as your practical checklist. We're moving from the how it works to the what you need. Use this guide to find a high-quality tool that fits perfectly, whether you're a doctor dictating patient notes or a podcaster transcribing your latest interview.
Foundational Accuracy and Language Support
Let’s start with the absolute deal-breaker: accuracy. A tool that constantly mishears you isn't a helper; it's a headache. It creates more work, defeating the entire purpose. Today’s best platforms consistently hit accuracy rates over 95% in good conditions, a number that’s only possible thanks to incredibly sophisticated AI.
But getting the words right is just the beginning. The software also needs to be a bit of a world traveler. Top-tier tools provide solid support for a wide range of languages, dialects, and accents. This isn't just a "nice-to-have"—it's essential for global teams, media companies, and any business serving a diverse customer base. A system trained on a broad dataset will understand a speaker from London just as clearly as one from Sydney or Boston.
This versatility often extends to the tool’s technical side, too. Many powerful speech to text solutions come packed with advanced voice converter features, giving them the flexibility to handle audio from all sorts of sources.
Advanced Capabilities for Professional Use
For most professionals, simple dictation just doesn't cut it. The real magic happens with the advanced features that are designed to handle the messiness of real-world audio. These are the tools that elevate a basic app into a true productivity powerhouse.
- Speaker Diarization: Ever try to figure out who said what in a meeting recording? This feature solves that. It automatically identifies each speaker and labels their dialogue (e.g., "Speaker 1," "Speaker 2"), making it a must-have for transcribing interviews, meetings, or focus groups.
- Custom Vocabulary: If you're a lawyer, doctor, or engineer, you know how frustrating it is when a tool butchers your industry-specific terms. A custom vocabulary lets you "teach" the software your unique jargon, product names, and acronyms, which can drastically boost its accuracy for your line of work.
- Real-Time Transcription: For live events, webinars, or critical client calls, seeing the text appear on screen as it's spoken is invaluable. It provides instant accessibility for your audience and allows for on-the-spot review and analysis.
When you put these features together, a great STT tool doesn't just write down words—it creates structure. It turns a tangled conversation into a clear, organized, and searchable document, saving you hours of painful manual clean-up.
Integrations and Workflow Automation
The best speech to text software doesn't operate in a vacuum. It should play nicely with the other tools you rely on every day, whether that means automatically sending a transcript to your Google Drive, a task to your Asana board, or a note to your CRM.
This kind of smooth integration is where you unlock serious productivity gains. When your STT software can push information where it needs to go on its own, you eliminate all that tedious downloading, copying, and pasting. For anyone looking to automate repetitive tasks, this is a massive win.
Ultimately, the right software should feel like a natural part of your workflow, not another clunky app you have to manage. It works quietly in the background, making sure your spoken words are captured, formatted, and delivered exactly where they need to be.
How Different Industries Use This Technology
The real magic of speech-to-text software isn’t just in its technical specs; it’s in seeing how it solves real-world problems. This isn't a generic tool. Its value truly shines when it’s put to work in specific professional fields, from the chaos of an emergency room to the high-stakes environment of a courtroom.
Let's break down a few of the key sectors where this technology is making a massive difference. Each example shows how it moves beyond being a simple productivity hack to become a fundamental part of the job.
Revolutionizing Healthcare Documentation
In healthcare, time is a currency you can't get back. Doctors and nurses are constantly battling a mountain of administrative work, which steals precious moments away from patient care. Speech-to-text software hits this problem head-on by completely changing how clinical notes get made.
Instead of slowly typing out every detail of a patient visit, clinicians can just speak their observations. This creates rich, comprehensive notes on the spot, capturing far more nuance than a quick, typed summary ever could.
- Problem Solved: It cuts down on the dreaded "pajama time," where doctors spend hours after work just catching up on paperwork.
- Key Benefit: This frees up medical staff to do what they do best: diagnose and treat patients. The result is better care and less burnout.
Of course, accuracy is everything here. That’s why specialized medical speech-to-text software is trained on vast medical vocabularies, ensuring complex terms like "myocardial infarction" are captured perfectly every single time.
Streamlining the Legal Sector
The legal world is built on words, and an accurate written record isn't a nice-to-have—it's essential. For decades, this meant painstakingly transcribing depositions, client meetings, and court proceedings, a process that was as slow as it was expensive.
Today, legal professionals use speech-to-text to get first-draft transcripts in minutes, not days. Lawyers can dictate case notes or draft contracts while walking to their car, radically accelerating how quickly they can work. This boost in efficiency helps them build stronger cases and ultimately serve their clients better.
Powering Media and Entertainment
For media companies, getting content in front of as many people as possible is the name of the game. Speech-to-text is the engine that drives closed captions and subtitles for everything from YouTube videos to live news broadcasts. This isn't just for audiences who are deaf or hard of hearing; it’s for anyone watching in a loud cafe or with the sound off on their phone.
By automatically generating a transcript, creators also make their content completely searchable. Think about it: you can instantly find the exact moment in a two-hour podcast where someone mentioned a specific topic. That’s the power of turning spoken audio into indexed text.
This capability breathes new life into old archives, making decades of audio and video recordings easy to search, repurpose, and monetize.
Enhancing Customer Service and Analytics
In customer service, the "voice of the customer" is a literal goldmine of insights. Contact centers use speech-to-text to transcribe and analyze every single customer call, turning a sea of audio data into actionable intelligence.
This is about much more than just keeping a record. By analyzing the transcribed text, businesses can:
- Spot Trends: Quickly identify recurring product flaws or common customer frustrations.
- Gauge Performance: Review calls to assess agent empathy and ensure they’re following compliance scripts.
- Refine Training: Use real-life call examples to coach agents on navigating tough conversations.
The rapid adoption across these fields is fueling incredible market growth. The speech-to-text API market is projected to jump from USD 3.87 billion in 2024 to USD 9.1 billion by 2029, a testament to its expanding role in everything from smart home devices to enterprise analytics. As reported by The Business Research Company, this growth highlights just how essential this technology has become to the way modern businesses operate.
Benefits Beyond Simple Word Processing

It’s easy to see the main appeal of speech to text software: it turns your spoken words into text. Simple, right? But looking at it as just a time-saver for typing really misses the point. The real magic happens with all the other doors it opens for individuals and businesses—from productivity boosts to powerful data analysis and greater inclusivity.
If you only see this software as a digital stenographer, you’re not seeing the full picture. It’s a tool that can genuinely change how we work, manage information, and even who gets to join the conversation. The advantages go way beyond convenience; they can be profoundly impactful.
Boosting Accessibility and Inclusion
One of the most powerful benefits is how much it improves accessibility. For someone with a physical disability, a motor impairment, or a condition like carpal tunnel that makes typing a painful chore, this software is a lifeline. It gives them the power to write emails, create documents, and navigate the web just as quickly and easily as anyone else.
Imagine a student with dysgraphia trying to write an essay. The traditional way is often a slow, frustrating battle. With speech to text, they can just speak their mind, letting their ideas flow freely without the physical roadblock of typing. It levels the playing field, allowing their actual knowledge to come through.
Key Insight: Speech to text software is more than a convenience; for many, it's an essential accessibility tool that breaks down barriers to communication and professional opportunities.
This is a huge reason for the explosive growth in related technologies. Just look at text-to-speech software, which often goes hand-in-hand with dictation tools. Its global market was valued at USD 3.19 billion in 2024 and is on track to hit USD 12.4 billion by 2033. A big part of that growth comes from the rising demand for assistive tools, as you can see in this comprehensive market analysis.
Unlocking a Goldmine of Searchable Data
Most businesses are sitting on a treasure trove of audio and video they can’t really use—think of all the recorded meetings, webinars, sales calls, and training sessions. Before transcription, this content is a "black box." If you needed to find one specific comment, you were stuck scrubbing through hours of recordings. It’s a tedious and wildly inefficient process.
But once you convert all that audio into text, you suddenly have a fully searchable, indexed archive.
- Before: A product manager needs to know what customers said about a feature in last quarter's focus groups. They block out a few days to re-listen to all the recordings.
- After: They type a few keywords into a search bar, and the exact quotes they need pop up in seconds from the transcribed files.
This simple change turns your audio library from a storage headache into a strategic asset. You can analyze customer feedback patterns, keep track of project decisions, and maintain compliance records without breaking a sweat. In specialized fields like healthcare, creating searchable patient notes is absolutely essential. You can learn more about how speech to text is used in the medical field in our guide on the topic.
This ability to pull up spoken information instantly can completely change how decisions are made, giving teams the power to act on data that used to be locked away. For business intelligence, it’s a total game-changer.
Got Questions About Speech-to-Text? We've Got Answers.
Even after seeing what speech-to-text software can do, it's completely normal to have a few practical questions. Most people wonder about things like accuracy, how it handles meetings, data security, and of course, cost.
Let's clear up those common questions so you can feel confident about whether this technology is the right fit for you.
How Accurate Is This Stuff, Really?
This is usually the first thing on everyone's mind, and for good reason. The best professional speech-to-text tools can hit accuracy rates above 95% under ideal conditions. Think of a clear speaker, a good microphone, and minimal background noise.
But real-world scenarios aren't always perfect. Heavy accents, people talking over each other, or a crackly phone line can definitely lower that number. That's why professional tools come equipped with features to fight back, like smart noise cancellation or custom vocabularies that you can "teach" specific names, acronyms, or industry jargon.
For anything mission-critical where every single word counts—like in the legal or medical fields—it’s still a smart move to have a human give the transcript a quick final review. This final polish ensures the document is absolutely perfect.
Can It Handle a Meeting with a Bunch of Different People?
Yes, and this is where modern software truly shines. The technology behind this magic is called speaker diarization (or speaker identification).
It works by picking up on the unique vocal patterns of each person in the conversation. From there, it automatically assigns what was said to the right person. Instead of getting one giant, confusing block of text, you get a clean, organized script.
It might look something like this:
- Speaker 1: "Okay, let's move on to the quarterly budget review."
- Speaker 2: "Sounds good. I have the preliminary numbers ready to share."
This feature is a game-changer for transcribing interviews, board meetings, or any group discussion. It transforms a chaotic conversation into a structured record that’s actually easy to read and understand.
Is My Data Safe with Cloud-Based Transcription Tools?
Any reputable software provider takes data security incredibly seriously, especially when they're handling sensitive business information. Top companies build their platforms with multiple layers of protection.
Here’s what you should expect:
- End-to-End Encryption: Your audio and text are scrambled and secured both while they're being sent to the server (in transit) and while they're stored there (at rest).
- Compliance Certifications: Look for providers who meet strict data privacy standards like GDPR in Europe or HIPAA for US healthcare.
- Access Controls: The platform should ensure that only authorized people on your team can ever view or manage the transcribed data.
Before you sign up for any service, always take a minute to review their privacy policy and security credentials. For organizations needing the highest level of control, some on-premise solutions keep all the processing inside your own private network, meaning your data never leaves the building.
What's the Real Difference Between Free and Paid Tools?
When you boil it down, the gap between free and paid speech-to-text tools comes down to four things: accuracy, features, security, and how much you can use them.
| Feature | Free Tools | Paid Tools |
|---|---|---|
| Accuracy | Good enough for personal notes, but not for professional work. | Much higher, often over 95%, and built for reliability. |
| Features | Just the basics—simple dictation and not much else. | Advanced capabilities like speaker diarization, custom vocabularies, and real-time transcription. |
| Security | Minimal security; may not be suitable for confidential information. | Robust encryption and compliance with standards like GDPR and SOC 2. |
| Limits | Usually have strict caps on file length or how much you can transcribe per month. | Generous or unlimited plans designed for heavy professional use. |
Free tools are great for firing off a quick email or jotting down a personal reminder. But for any professional, high-volume, or sensitive work, investing in a paid tool gives you the accuracy, advanced features, and peace of mind you need to do the job right.
Ready to see how a secure, professional-grade dictation platform can transform your workflow? Whisperit uses advanced AI to help you create accurate documents up to two times faster, all while protecting your data with Swiss hosting and full GDPR compliance. Start streamlining your documentation today with Whisperit.ai.